How to Get Freaky Fonts and Optimize Delivery
Freaky fonts are becoming an essential part of modern d...







Choosing the right cloud data center location impacts your business's performance, costs, compliance, and resilience. Here's what you need to know:
To make the best choice, consider the location's proximity to users, compliance needs, cost factors, and disaster recovery options. Tools like latency tests, workload analysis, and compliance certifications can help you decide.
With over 17 data centers globally, providers like SurferCloud offer flexible options to meet these needs while balancing performance and budget.
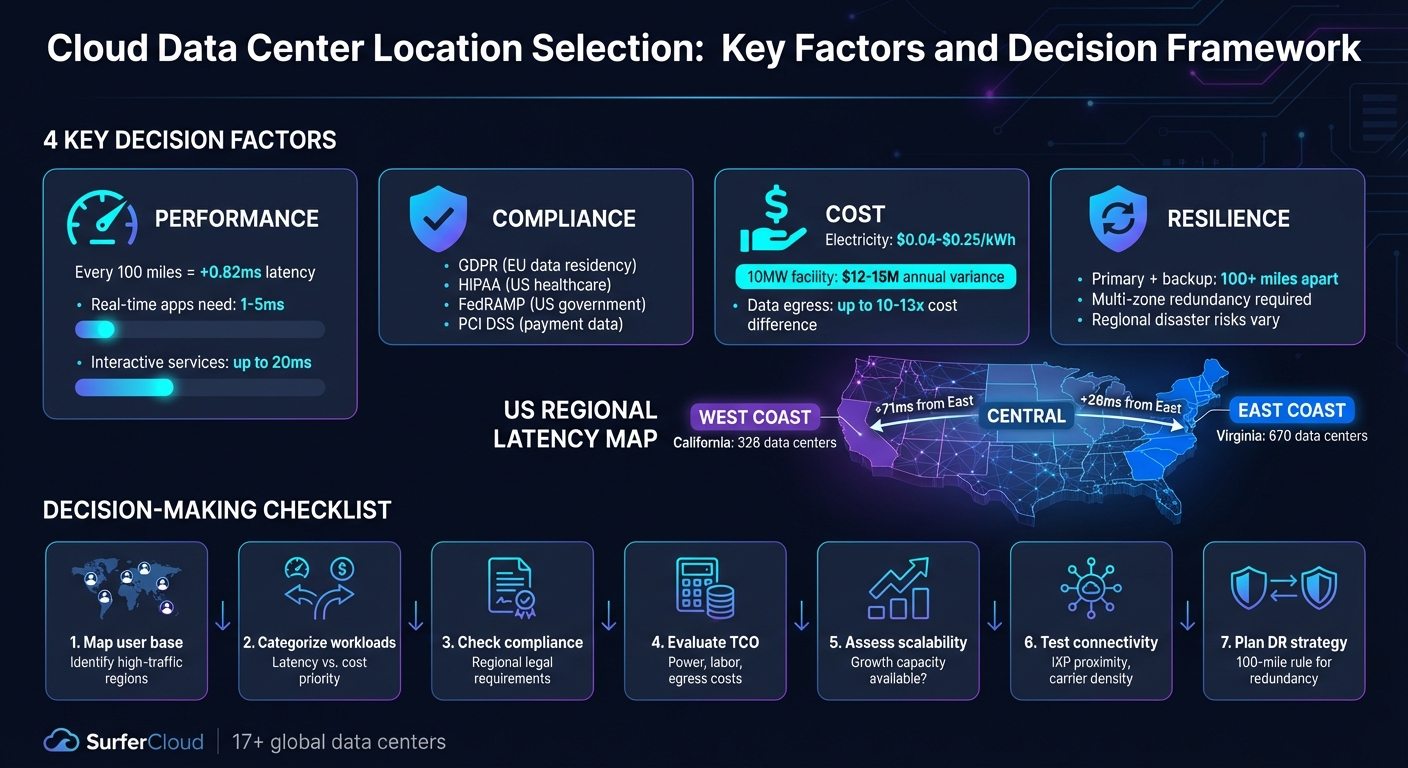
Cloud Data Center Location Selection: Key Factors and Decision Framework
Your business objectives play a big role in determining where your cloud infrastructure should be located. For example, real-time trading platforms thrive on ultra-low latency, making proximity to users absolutely essential. On the other hand, if your focus is on batch analytics that run overnight, you might prioritize lower electricity costs over being close to major user hubs.
Bob Spiegel from QuoteColo explains it well: "A strategic data center location strategy goes far beyond simple geography - it's about optimizing the complex interplay between proximity, performance, risk, and cost to achieve your specific business objectives." [6]
For businesses in the U.S., this means considering factors like power costs, which can vary dramatically from $0.04/kWh to $0.25/kWh depending on the state [6]. Compliance requirements also come into play - think HIPAA for healthcare or financial regulations for banking. Additionally, understanding where your users are located is key. For instance, a SaaS company serving customers along the East Coast might prioritize Virginia for its proximity to major population centers. Meanwhile, a business focused on cutting costs might target areas with lower electricity rates and tax incentives. These considerations form the foundation for evaluating workload-specific needs.
Once you've clarified your business goals, the next step is to assess how the demands of each workload influence your location strategy. Different applications have different needs, and your approach should reflect that. For instance, latency-sensitive workloads - like online gaming or video conferencing - require low latency (typically 1–5ms). To meet this need, data centers should be located as close to users as possible. In contrast, data-intensive workloads, such as machine learning, benefit from facilities with specialized GPU instances and high-density power infrastructure [6].
Compliance-driven applications often come with strict geographic requirements. For example, handling European customer data may require compliance with GDPR’s data residency mandates, while healthcare providers must ensure their infrastructure aligns with HIPAA standards. On the other hand, throughput-intensive tasks - like large-scale backups - can tolerate higher latency but need regions with affordable power and scalable infrastructure. These workload-specific insights are crucial for creating a targeted checklist.
To make an informed decision, start by mapping your user base to identify high-traffic regions and determine where proximity matters most. Then, categorize your workloads based on their latency tolerance. Real-time applications should take priority for proximity, while batch processing can focus on cost efficiency.
Pay attention to grid reliability and power capacity, especially for AI workloads [7]. Ensure your provider offers all the necessary services in a single location to avoid the added complexity and expense of inter-region transfers [1].
Don’t overlook the 100-mile rule for disaster recovery: keep your primary and backup facilities at least 100 miles apart to reduce the risk of a single regional event disrupting both sites [6]. Finally, check for carrier density and proximity to Internet Exchange Points (IXPs). These factors ensure competitive network pricing and provide the redundancy needed for a robust infrastructure [6].
Latency plays a critical role in understanding how quickly data travels between users and servers. To measure this, Round-Trip Time (RTT) is a key metric. While ICMP pings provide an idealized view of latency, TCP Ping (Layer 4) gives a more realistic picture of real-world performance challenges [10].
"TCP has more speed bumps... TestMy Latency is more sensitive than your typical ICMP ping for real connection issues." - TestMy.net [10]
For example, fiber optic cables introduce a delay of about 0.82 milliseconds per 100 miles [2]. This means a server in Dallas might respond to a user in Austin in just 5.44 milliseconds, but the same server could take 38.65 milliseconds to respond to a user in New York [12]. Tools like Google Analytics can help you identify high-traffic regions, enabling you to focus on optimizing performance where it matters most [1].
It's also essential to test latency under both idle and load conditions. This helps identify performance drops when network demand is high [11]. For applications like video conferencing, monitoring jitter (variations in RTT) and packet loss is equally important, as these factors can significantly affect real-time communication [11].
Once latency is assessed, the next step is ensuring stable and reliable connectivity.
While physical proximity to users reduces latency, the quality of the network infrastructure is what ensures consistent and reliable data delivery. Data packets rarely take a direct path between two points, as they follow physical cable routes that can be much longer than the straight-line distance [2]. Facilities near major Internet Exchange Points (IXPs) - often referred to as carrier hotels - are key to improving connectivity. These locations offer multiple routing options and competitive pricing thanks to a dense concentration of providers [8].
For businesses looking to enhance performance, using a global private network can bypass the congestion of the public internet, maintaining higher Quality of Service [1]. In the U.S., focusing on tier 1 markets like Ashburn (Northern Virginia) and Silicon Valley (Northern California) is a smart move due to their extensive interconnection options [8]. For context, Virginia leads with 670 data centers, followed by Texas with 429 and California with 326 [8].
To further safeguard reliability, implementing multi-zone redundancy is crucial. This involves distributing resources across multiple zones within a region, offering protection against localized outages caused by power, cooling, or network failures [3].
With these connectivity considerations in mind, selecting the right locations becomes a more strategic decision.
When serving U.S. users, choosing the right deployment locations can make a significant difference in performance. The U.S. is typically divided into three regions: East, Central, and West. To achieve low latency across the country, many businesses deploy infrastructure in all three regions [8]. However, if your user base is concentrated in specific areas, you can tailor your approach. For instance, businesses targeting East Coast users often select Northern Virginia for its proximity to major population hubs and robust connectivity, while those focused on the West Coast frequently opt for Northern California.
Routing delays vary by region. For example, sending data from the East Coast to the Central U.S. adds about 28 milliseconds, while routing to the West Coast increases latency by around 71 milliseconds [13]. Applications requiring near-instantaneous responses - like financial trading or online gaming - demand latencies between 1–5 milliseconds, making proximity a top priority [6]. Meanwhile, interactive services such as e-commerce can tolerate latencies up to 20 milliseconds, and batch processing tasks can handle delays beyond that [6].
To further enhance performance, Content Delivery Networks (CDNs) and Regional Edge Caches are effective tools. They store frequently accessed content closer to users, reducing the distance data needs to travel [5]. For businesses serving a global audience from a single region, U.S. locations are often ideal due to their strong international connectivity [9].
Where you deploy your infrastructure often hinges on compliance requirements. In the U.S., businesses face a variety of regulatory frameworks, such as HIPAA for healthcare, PCI DSS for payment systems, and FedRAMP for federal workloads [16][18]. Financial institutions must also adhere to additional mandates like the CFPB's open banking rules, which require secure data sharing with authorized third parties starting April 1, 2026 [14].
Data residency laws further complicate matters. U.S. regulations often mandate that certain data remain within the country or prohibit its transfer abroad. These laws span national security, export controls, and even specific tax or employment record requirements [14]. To meet these demands, cloud providers divide their operations into "geographies", which act as strict data residency zones to ensure compliance [15][4]. For organizations with more rigorous needs, sovereign cloud geographies offer isolated environments tailored to meet regional legal requirements [4].
"The cloud is borderless, but regulations are not." - Cogent Infotech [16]
Before choosing a location, confirm that the necessary compliance certifications are active for that site. Under the shared responsibility model, cloud providers secure the infrastructure, but you are responsible for configuring workloads, managing identities, and ensuring compliance [16]. A cautionary example: in 2023, Meta faced a €1.2 billion fine under GDPR for mishandling cross-border data transfers [16]. To avoid such pitfalls, implement tiered compliance measures - use stringent security protocols and frequent audit logging for high-risk data, while opting for economical storage solutions for less sensitive information [16].
| Regulatory Framework | Primary Focus | Key Requirement for Location Selection |
|---|---|---|
| GDPR | EU Personal Data | Data must stay within the EU or approved jurisdictions [16][6] |
| HIPAA | U.S. Healthcare | Requires strict access controls and long-term patient record retention [16][6] |
| FedRAMP | U.S. Government | Infrastructure must meet federal security standards [16] |
| PCI DSS | Payment Information | Demands extensive logging and physical data security [16] |
| CFPB Open Banking | Financial Data | Secure data sharing with authorized third parties by 2026 [14] |
Once compliance is addressed, it’s essential to evaluate physical and environmental risks tied to your chosen location.
While compliance dictates where data must reside, the local environment can significantly impact data center operations. Natural disasters and environmental risks vary by region. For instance, the Atlantic and Gulf Coast face hurricanes, the Midwest and Southeast deal with tornadoes, the West contends with wildfires and mudslides, and the Pacific Basin must prepare for earthquakes and tsunamis [6]. Although cloud providers conduct thorough regional risk assessments, understanding these vulnerabilities is crucial [19].
Operational costs are another factor to consider. Power prices and water usage differ widely across regions, with a 10MW data center potentially facing $12–15 million in annual cost variations due to regional power rates [6]. Concerns over energy use, noise, and environmental impact have already delayed or blocked at least 16 major data center projects [17].
"Virginia is the data center capital of the world, and we should not enact legislation to allow other states to pass us by nor to restrict local government from developing data centers based on their community's specific circumstances." - Glenn Youngkin, Governor of Virginia [17]
Modern cloud architecture leverages Availability Zones (AZs) - separate facilities within a region with independent power, cooling, and networking to isolate faults [15][4]. To safeguard critical applications, choose regions offering AZs and ensure infrastructure hardening measures, such as N+1 redundancy, multiple utility connections, and automated fire suppression systems, are in place [19].
Geographic redundancy is key to protecting your business from regional disasters. By placing primary and backup facilities far enough apart, you can minimize the risk of a single event affecting both locations - an essential element of disaster recovery planning [6]. With 4,311 data centers spread across the U.S. as of late 2025, there’s no shortage of options for strategic placement [8].
Your disaster recovery strategy should align with your tolerance for downtime and data loss. Options range from cost-effective backup and restore methods (24+ hours recovery) to high-performance multi-site active/active setups (near-zero downtime, but at a higher cost) [20].
In October 2025, Authress, an identity service provider, successfully maintained its SLA during a major AWS outage by employing a reliability-first design. CTO Warren Parad explained how their DNS dynamic routing strategy allowed automatic switching between two regions. Their custom monitoring solution evaluated latency and database health across six regions, bypassing default health checks that could fail during infrastructure outages [19].
"Simply put - our strategy is to utilize DNS dynamic routing. This means requests come into our DNS and it automatically selects between one of two target regions, the primary region that we're utilizing or the failover region in case there's an issue." - Warren Parad, CTO, Authress [19]
To ensure resilience, develop custom health checks that monitor your entire system rather than relying solely on provider-default endpoints. Use Infrastructure as Code (IaC) tools to redeploy infrastructure quickly in a recovery region, minimizing Recovery Time Objectives (RTO) [20]. Regular disaster recovery simulations and automated tests are essential to validate your Business Continuity Plan (BCP) and confirm that your RTO and Recovery Point Objectives (RPO) are achievable [20][21].
When planning your infrastructure, understanding the Total Cost of Ownership (TCO) is crucial. This includes not just direct expenses like compute, storage, and networking, but also operational costs, which can vary widely depending on location. For instance, electricity prices range from $0.04/kWh to $0.25/kWh depending on the region [6]. Even a slight difference in power rates can translate into millions of dollars in annual expenses.
Don’t overlook hidden costs like data egress fees and real estate expenses. Transferring 50 TB of data out of a network can cost up to 10–13 times more with some providers than others [23]. Similarly, real estate in prime data center locations can cost up to 10 times more than in secondary markets [6]. However, regional tax incentives and economic grants can help offset these costs [6][22].
Labor and migration costs also add up. Hiring architecture specialists, optimizing applications, and training staff are all part of the equation [23]. To get a clear picture of your TCO, use vendor-specific pricing tools to compare costs across different regions before finalizing a location [22][23][18]. This analysis is essential to finding a location that fits your budget while meeting performance and compliance needs.
Scalability is another key factor to consider. Choosing a location with room for growth can save you from costly migrations later. Can the facility handle expansion easily? Power and cooling capacity play a major role, especially with high-density workloads like AI, which already make up about 20% of data center capacity [25].
The speed at which you can scale is also critical. Remote locations or those with limited staffing might face delays in shipping equipment or setting up operations [2]. Modular data centers offer a faster solution, with deployment times up to 50% quicker than traditional builds [25]. Be sure to check regional resource quotas early, as a lack of quotas can halt growth even if physical capacity is available [9].
Set specific thresholds for auto-scaling based on metrics like CPU usage, memory, or queue length instead of relying on default settings [24][26]. Regular scalability tests can help you spot bottlenecks before they disrupt operations [24]. Keep in mind that network latency increases by about 0.82 milliseconds for every 100 miles data travels [6][2], so staying close to your users is essential as you scale. Once scalability is ensured, operational and logistical considerations take center stage.
After addressing scalability, it’s time to focus on operational efficiency. The ability to quickly deploy and maintain infrastructure is critical. Proximity to your main operations base can reduce travel time and shipping delays for equipment [2]. Evaluate the local labor market to ensure you can find skilled technical staff at competitive rates [6].
Power reliability is another major factor. Electricity accounts for 25%–60% of operational expenses [7], so grid stability and the track record of utility providers are key considerations [6]. Quick access to vendors, contractors, and support services can minimize downtime during emergencies [6]. Carrier-neutral facilities offer flexibility by allowing you to choose among multiple network providers, which can help lower connectivity costs [6].
For applications where low latency is critical, consider premium network tiers that use private global networks instead of the public internet [9]. If sustainability is part of your strategy, look into carbon-free energy (CFE%) percentages when selecting a location [9]. SurferCloud’s network of 17+ global data centers provides flexible deployment options and 24/7 expert support, helping you balance these operational needs while maintaining performance and cost-efficiency.
When selecting a location, focus on minimizing latency - every additional 100 miles adds about 0.82 ms [2][6]. Ensure compliance with legal mandates [6][4], manage costs by considering variations in electricity and real estate expenses [6], and maintain resilience by separating primary and backup facilities by at least 100 miles [6].
To streamline location selection, develop a consistent and systematic approach. Start by clearly defining business goals, mapping out user locations, and identifying latency requirements. Use an MCDA framework to evaluate potential sites based on connectivity, disaster risks, and compliance factors [6]. Build detailed TCO models that account for power, labor, and data transfer costs. Regularly revisit and refine your strategy - every two years is a good benchmark - to adapt to changing needs [6]. Document your criteria and scoring methods to ensure future teams can follow the same process with ease.

SurferCloud simplifies your deployment strategy with a network of over 17 global data centers. Spanning key regions like the Americas, Asia Pacific, and EMEA, with facilities in cities such as Los Angeles, Singapore, Frankfurt, and London, SurferCloud brings computing, storage, and networking resources closer to your users. Its elastic infrastructure scales with your needs, and 24/7 support ensures you can execute your location strategy effectively and confidently. With SurferCloud, you’re equipped to implement a streamlined, strategic plan for success.
Laws like the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA) heavily influence where cloud data centers can be located. These regulations are designed to ensure sensitive data is handled securely and within regions that meet specific legal and security standards.
Take GDPR as an example - it requires that data belonging to EU residents either stays within the European Economic Area or is transferred using approved frameworks like Standard Contractual Clauses. Similarly, HIPAA mandates that protected health information (PHI) in the U.S. must be stored on servers that meet stringent security requirements and include a signed Business Associate Agreement (BAA).
Selecting a location that complies with these laws is essential for avoiding fines, legal complications, and operational disruptions. Businesses need to evaluate regional regulations, certifications, and data sovereignty rules carefully to ensure their cloud infrastructure not only meets legal obligations but also balances performance and cost effectively.
When deciding on a cloud data center location, one of the key factors to consider is how proximity to users affects performance. For every 100 miles between your users and the data center, latency increases by approximately 0.82 milliseconds. By choosing a location closer to your primary audience, you can boost response times without the need for costly network upgrades. Additionally, some regions offer more affordable rates for services like storage, compute, and data transfer, helping you balance performance with your budget.
It’s also crucial to analyze local operating costs, which can vary significantly across the U.S. Factors like energy rates, tax incentives, and real estate prices should be part of your evaluation. For example, areas with lower electricity costs or favorable tax policies can reduce your overall operational expenses. Don’t forget to account for disaster risks, such as vulnerability to earthquakes or tornadoes, as these can impact downtime and increase insurance costs.
Finally, make sure the location aligns with your compliance and scalability needs. If your business must follow regulations like HIPAA or FedRAMP, you’ll need to prioritize regions with the required certifications, even if they aren’t the closest to your users. By weighing factors like latency, pricing, operating costs, and compliance, you can strike the right balance between performance and cost-effectiveness for your cloud infrastructure.
To ensure your data center location supports disaster recovery and keeps your business running during disruptions, focus on geographic redundancy. This means choosing at least two locations in different regions. By doing so, you safeguard against regional outages caused by power failures, extreme weather, or other unexpected events. Make sure these locations also meet regulatory requirements, such as storing data and encryption keys within specific jurisdictions.
Build a strong strategy by incorporating automated replication, regular failover testing, and clearly defined recovery time objectives (RTOs). Automated systems reduce the risk of human error and allow for faster recovery during emergencies. It's also crucial to evaluate natural disaster risks - steer clear of areas prone to earthquakes, flooding, or severe storms. While deploying across multiple regions may come with higher costs, this investment is often far less than the financial hit of prolonged downtime. Combining redundancy, automation, and risk management creates a robust plan to keep your operations steady, even when the unexpected happens.





