What is CDN (Content Delivery Network)? Defin
In today’s digital age, website and application perfo...







Real-time personalization uses AI to instantly tailor online experiences based on user actions like clicks, scrolls, or purchases. This technology processes live data in milliseconds, ensuring recommendations or updates feel immediate and relevant. Businesses leveraging this see major benefits, such as a 10%-40% revenue boost and $20 ROI for every $1 spent on personalized marketing.
Key highlights:
This approach requires robust cloud architecture, precise AI models, and compliance with data privacy laws like CCPA. With the right setup, businesses can deliver fast, tailored experiences that drive user satisfaction and conversions.
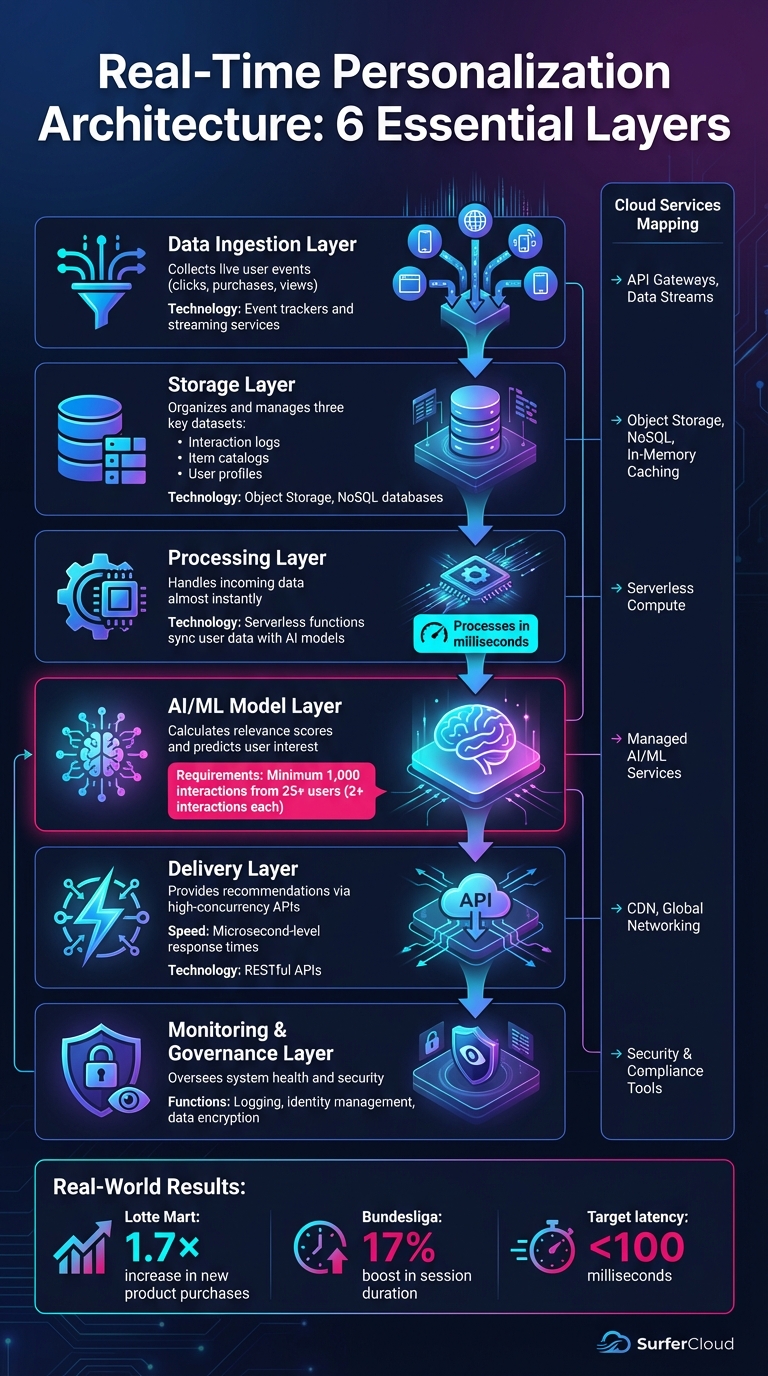
Six-Layer Architecture for Real-Time AI Personalization in Cloud Services
Real-time personalization thrives on speed, and its architecture is built around multiple functional layers working seamlessly together.
Real-time personalization systems utilize six essential layers to capture, process, and deliver customized user experiences. The data ingestion layer collects live user events - like clicks, purchases, and views - through event trackers and streaming services, feeding this data into the system as it happens. The storage layer organizes and manages three key datasets: interaction logs, item catalogs, and user profiles.
The processing layer handles incoming data almost instantly, using serverless functions to sync user data with AI models. At the heart of the system is the AI/ML model layer, where algorithms calculate relevance scores, predicting the likelihood of a user's interest in specific items. The delivery layer then uses APIs designed for high-concurrency events to provide recommendations with microsecond-level response times. Finally, the monitoring and governance layer oversees system health, employing tools like logging, identity management, and data encryption to maintain security and reliability.
For these systems to function effectively, the AI models require at least 1,000 interaction records from a minimum of 25 unique users, with each user having at least two interactions[7]. Companies like Lotte Mart and Bundesliga have already seen the benefits - Lotte Mart reported a 1.7× increase in new product purchases, while Bundesliga noted a 17% boost in session durations after adopting personalized content[6].
Next, let’s explore the cloud services that make each of these layers possible.
Each layer in the personalization architecture relies on specific cloud services tailored to its tasks. For instance, the ingestion layer uses API gateways and data streams to capture user events, while the storage layer employs object storage, NoSQL databases, and in-memory caching for fast data retrieval.
| Layer | Cloud Service Type | Role |
|---|---|---|
| Ingestion | Networking / Streaming | Captures live events and streams them to the backend |
| Storage | Object Storage / NoSQL | Manages interaction logs and provides fast-access metadata |
| Processing | Serverless Compute | Executes data transformations and AI workflows |
| Inference | Managed AI / ML | Hosts trained models and provides recommendation APIs |
| Delivery | CDN / Global Networking | Delivers results from the nearest data center |
SurferCloud plays a critical role here, offering elastic compute, storage, CDN, and security solutions that align with each architectural layer. Its global presence ensures low latency and high performance, even for demanding workloads.
Geographic distribution is vital for real-time personalization. Systems must analyze data in milliseconds to deliver relevant content before users lose interest. For example, when a returning shopper visits an e-commerce site, the system needs to instantly recognize them and update the homepage with personalized product recommendations, such as items in their preferred sizes and styles. This kind of in-session personalization works best when computing resources are located close to the user.
By spreading compute and data nodes across multiple availability zones, organizations can maintain high availability and reduce latency. This approach is particularly effective during high-traffic events like flash sales, where millions of events need to be processed per second without delays. Such infrastructure has been linked to conversion rate increases of up to 198% from personalized user journeys[5].
SurferCloud’s network of 17+ global data centers ensures that computing resources are strategically positioned to serve users in the United States and beyond. This setup guarantees sub-second response times, enabling seamless delivery of personalized content.
Building on our earlier discussion about architecture, certain technical requirements must be met to ensure real-time personalization delivers on user expectations. These specifications refine how systems manage performance and data strategies, focusing on the key elements of data quality, system performance, and deployment architecture.
Real-time personalization hinges on three main datasets: interactions (like clicks and purchases), items (including details such as price and category), and user profiles (metadata like age and location). The freshness of this data is critical, as it directly impacts the accuracy of recommendations[7].
To kickstart a personalization model, you’ll need a baseline dataset: at least 1,000 interaction records from a minimum of 25 unique users, with each user logging at least two interactions[7]. This ensures the AI has enough data to identify meaningful patterns. However, this is just the starting point. Models need regular updates - ideally every one to two weeks - to stay relevant and adapt to changing user preferences[7].
One of the trickiest hurdles is identity resolution. Systems must track anonymous users through session IDs and later link their activity to a permanent user ID once they log in. This ensures that any browsing activity before login contributes to a more personalized experience afterward[10]. Real-time event streaming via APIs plays a crucial role here, allowing systems to update recommendations within seconds of a user action, delivering a dynamic and responsive experience[10].
Speed is everything in real-time personalization. Users expect recommendations powered by machine learning to be delivered in under 100 milliseconds, even during high-traffic periods[2]. This becomes even more challenging during traffic surges, such as when a single campaign launch causes a 10x spike in activity. To handle this, infrastructure must scale automatically without manual intervention[2]. Cloud services are key here, enabling automatic resource scaling during events like Black Friday sales or major product drops, and scaling back during quieter times to save costs.
Caching is another lifesaver for managing backend load. A two-layer caching approach works best: per-node caching to cut down on deserialization costs and global distributed caching to prevent backend overload. Techniques like the "stale-while-revalidate" pattern also help avoid "cache stampedes", where expired cache entries could otherwise trigger thousands of simultaneous database requests, potentially crashing the system[2].
SurferCloud offers a practical way to address these technical challenges. Its deployment pattern integrates several advanced services to streamline real-time personalization. The ingestion layer captures live user events through API gateways, sending them to the processing layer for analysis. Elastic compute servers manage the heavy lifting of AI model training and inference, automatically scaling to meet demand. Meanwhile, NoSQL databases store interaction logs and user profiles, offering fast data access, and in-memory caching ensures item metadata can be retrieved in microseconds during recommendation generation.
For fast delivery, the CDN and networking layer serves recommendations from the nearest data center. With over 17 global locations, SurferCloud ensures sub-second response times for users across the United States and beyond. Security measures are robust, with data encryption at rest using key management services and TLS encryption securing all API communications[4]. Serverless functions encapsulate recommendation logic, providing RESTful APIs that web and mobile frontends can query without requiring developers to manage the underlying infrastructure[7].
The system also supports graceful degradation. If real-time queries fail or timeout, fallback models kick in to maintain a personalized experience rather than disrupting it[2]. Monitoring tools track critical metrics like GetRecommendationsLatency and PutEventsRequests, helping maintain performance standards and flagging potential bottlenecks before they affect users[4].
Personalization in AI hinges on the specific goals you’re aiming to achieve and the data at your disposal. For example, user personalization algorithms analyze past interactions - like clicks or purchases - to recommend items for landing pages. This approach requires detailed interaction logs. Meanwhile, related item models use catalog metadata to suggest similar products, perfect for "more like this" features. If you’re looking to tailor search results or existing lists, personalized ranking reorders them based on individual preferences. Lastly, user segmentation clusters customers with shared interests, enabling targeted marketing campaigns. The technique you choose depends on your use case: user personalization works well for homepage experiences, while personalized ranking is ideal for refining search results.
Once you’ve selected an AI technique, the model lifecycle in a cloud environment defines how it evolves - from data preparation to deployment. It starts with data preparation, where schemas are set up to organize interaction logs, catalog details (like price and category), and user demographics (such as age or location) [7]. Next comes model training, which involves selecting pre-built algorithms, often referred to as "recipes", tailored to your specific needs. Once trained, the model - known as a "solution version" - is deployed as a campaign, complete with a private API endpoint for delivering real-time recommendations [7].
To keep the model relevant, regular updates are crucial. For new users without any interaction history, the system initially suggests popular items until it gathers enough live data. Continuous monitoring ensures smooth operation, with metrics like GetRecommendationsLatency and DatasetImportJobError helping to flag potential issues before they affect users [4].
After deployment, integrating the AI model into real-time decision flows becomes the next step. API endpoints play a central role here, delivering recommendations through microservices or serverless functions. This setup keeps your frontend code streamlined while allowing the personalization layer to scale independently [7][11]. For example, when a user loads a page, an API call fetches scored recommendations in just milliseconds [8].
Real-time event streaming makes this process even smarter. By capturing user interactions - such as clicks, views, or purchases - via an event tracker, these insights are sent back to the model using APIs like PutEvents. This enables the system to adjust its recommendations instantly based on the latest user behavior. Business logic can further refine results, filtering out-of-stock items, recently purchased products, or those that don’t align with active promotions [7][8].
SurferCloud’s elastic compute servers make all this possible by automatically scaling resources to manage both training and inference workloads, even during traffic spikes. With data centers in over 17 global locations, API responses are delivered with sub-second latency, ensuring users in the United States and beyond experience real-time responsiveness. To safeguard data, encryption is applied at rest using managed keys, and all API communications rely on secure TLS/HTTPS protocols [4].
Real-time personalization involves handling sensitive user data, making adherence to U.S. privacy laws a must. The California Consumer Privacy Act (CCPA) is one of the strictest data privacy regulations in the country, requiring businesses to provide clear opt-out options and honor requests for data deletion [12][13]. Unlike voluntary guidelines, the CCPA carries legal obligations that businesses must follow.
A core principle in compliant personalization is data minimization - collecting only the data necessary for the intended use. For instance, if you're building a recommendation engine, you only need interaction logs, catalog metadata, and basic user preferences. There's no need to store sensitive details like social security numbers or medical histories [13][15].
Consent management is another critical element. Under CCPA and SOC 2, businesses must obtain explicit consent before collecting data, particularly if the data will be used beyond its original purpose [13]. Transparency is key - users should know exactly what data is being collected and how it will be used. Companies using unified privacy platforms have reported cutting audit times in half and closing deals 40% faster by demonstrating compliance readiness [12]. Additionally, privacy-by-design - embedding privacy controls into projects from the start - has become a standard practice under GDPR and is highly recommended for U.S. implementations [13].
While compliance ensures legal data practices, strong security measures are essential to protect these personalized interactions.
Securing data in cloud-based personalization requires a multi-layered approach. This process often operates under a shared responsibility model, where the cloud provider secures the infrastructure, and the organization manages its data, access controls, and compliance [14].
Start with Identity and Access Management (IAM) by applying Role-Based Access Control (RBAC) and adhering to the principle of least privilege. This means granting users and service accounts only the permissions they need for their specific tasks. For example, your data science team might have read-only access to training datasets but no ability to modify production APIs [15][16].
Network isolation is another key measure. Keep traffic off the public internet by running workloads inside Virtual Private Clouds (VPC) with private endpoints. Providers like SurferCloud offer VPC configurations and secure connectivity across their global data centers, ensuring low-latency performance while protecting APIs from unauthorized access [14][15].
Encryption is non-negotiable. Use encryption both at rest and in transit to secure data. SurferCloud, for instance, uses managed keys for encryption at rest and ensures API traffic is protected with TLS protocols. Beyond encryption, safeguard your systems against data poisoning attacks by implementing content filtering and input validation. These measures prevent malicious inputs from compromising the performance of your AI models [15][16].
Real-time personalization offers clear advantages, such as improved engagement and increased revenue, but it also introduces risks like privacy concerns and infrastructure challenges.
| Aspect | Benefits | Risks |
|---|---|---|
| Data Collection | Better engagement and product discovery [7][9] | Privacy breaches, data leaks, and non-compliance with CCPA/GDPR [15][16] |
| Model Training | Adapts quickly to changing user interests [7] | Vulnerable to data poisoning attacks that degrade performance [15] |
| Automated Output | Higher conversion rates, less manual effort [7] | Risks of algorithmic bias or exposing sensitive information [15][16] |
| Infrastructure | Streamlined operations via automated ML pipelines [7] | Managing large data volumes can strain IT resources |
Striking the right balance between security and innovation is crucial.
"Overly restrictive security measures might protect data but also impede innovation and slow down development cycles." - Google Cloud Architecture Center [15]
To maintain this balance, consider de-identification techniques like pseudonymization or bucketing. These methods help protect individual privacy while keeping the data useful for AI models [15]. Maintain detailed data lineage records to track how data moves, changes, and is accessed - essential for compliance and troubleshooting [15]. Finally, enable continuous monitoring with audit logs to detect unauthorized access and unusual activity in real time [14][15]. By implementing these strategies, businesses can harness the benefits of real-time personalization while keeping risks in check.
To maintain performance and control cloud costs, precise measurement and optimization are essential when dealing with real-time personalization.
To assess how well your personalization efforts are working, track a mix of online and offline metrics. Online metrics like CTR (Click-Through Rate), conversion rate, AOV (Average Order Value), and retention measure immediate user engagement. Offline metrics such as Coverage, MRR at 25, and NDCG at K evaluate the ranking quality of your models [18][1][19].
Technical performance metrics are equally important to ensure smooth cloud operations. For example:
GetRecommendationsLatency tracks how quickly recommendations are delivered.PutEventsRequests measures the volume of event tracking.DatasetImportJobError helps catch data pipeline issues early [4][17].When evaluating models, metrics like Area Under the Curve (AUC) highlight relevant user actions, while "Hit at K" and "Recall at K" measure how accurately users are segmented [18]. Keep in mind that Amazon Personalize requires at least 1,000 interaction records from 25 unique users, each with at least two interactions, to function effectively [7].
Once these metrics are in place, effective monitoring becomes critical to make timely adjustments.
Monitoring ensures your system remains responsive while also helping to manage costs. Tools like Amazon CloudWatch can track latency, throughput, error rates, and resource usage [17][20]. Set up automated alarms with Amazon SNS to notify your team when key metrics - such as recommendation latency or dataset import errors - exceed acceptable thresholds [4][17].
To optimize workflows, use network observability tools to visualize your system's topology and identify high-latency paths that may delay real-time delivery [20]. Application profiling can pinpoint components with high CPU or memory usage, allowing you to optimize resource allocation [20]. Linking performance metrics to data and model lineage is another powerful strategy, as it enables you to trace outputs back to specific configurations for iterative improvements [21]. Lastly, aim to re-train your personalization models every one to two weeks, depending on how much new interaction data is generated [7].
Balancing high-quality personalization with cost efficiency requires strategic planning. Start by rightsizing your resources and using dynamic autoscaling to adapt to real-time demand. Lightweight containers can further help match infrastructure needs to workload requirements [22][23].
During development, test hypotheses with smaller models and representative data subsets before scaling up. This approach reduces initial compute and storage costs [22]. To save on ongoing costs, consider these methods:
Personalization is evolving rapidly, moving beyond static suggestions to dynamic, AI-powered interactions that adapt to live user behavior [2]. With 71% of consumers expecting tailored experiences and 76% feeling frustrated when those expectations aren’t met, businesses that get personalization right can see revenue increases of 10% to 15% [3].
To meet these demands, technical capabilities are advancing. Achieving response times under 100 milliseconds is now a baseline requirement, made possible through techniques like parallel processing and multi-layer caching [2]. In March 2025, Logan Goulett, Salesforce’s Director of Software Engineering, highlighted how their Decisioning Pipeline and Recommendations Services (DPRS) hit this latency benchmark using these strategies [2].
"As AI-driven customer engagement continues to evolve, DPRS will play a key role in ensuring that every interaction is intelligent, responsive, and deeply personalized in real time." - Logan Goulett, Director of Software Engineering, Salesforce [2]
This shift in technology is setting the stage for scalable and future-ready personalization. Providers like SurferCloud are pivotal in this transformation, offering elastic scalability to handle unpredictable traffic spikes during major events [2][3]. With a global infrastructure, SurferCloud ensures low-latency performance and robust security, enabling the safe processing of sensitive personalization data while adhering to regional compliance standards. Their on-demand scalability allows businesses to innovate without sacrificing speed or security, equipping them to meet both current and future personalization challenges.
Looking ahead, personalization will deepen further with the integration of emerging technologies. Trends like conversational AI, immersive AR/VR experiences, and large language models for unstructured data analysis promise to redefine customer engagement [24][1]. However, challenges such as maintaining real-time data freshness - ensuring recommendations adjust instantly as preferences or inventory change - remain critical [2]. By investing in unified, scalable cloud ecosystems and intelligent caching strategies, businesses can consistently deliver the seamless, context-aware experiences that today’s consumers demand.
Real-time personalization taps into AI-driven insights to adjust content, recommendations, and offers based on each user's behavior, preferences, and interactions. By offering experiences that are timely and relevant, businesses can create stronger connections with customers and see a noticeable increase in engagement and conversions.
This kind of customization isn't just about making users feel special - it delivers measurable results. In fact, it can increase revenue by up to 40%, as people are far more likely to engage with content that feels tailored specifically to them. Using cloud platforms for real-time personalization also ensures the process is fast, scalable, and capable of managing large data loads without sacrificing performance.
Real-time AI personalization hinges on a mix of low-latency, event-driven tools and a cloud-based infrastructure. It all starts with capturing user actions - like clicks, views, or purchases - as they happen. These interactions are processed instantly using event streaming technologies and stored in high-speed, in-memory databases, ensuring AI models can access them without delay.
AI models, hosted on platforms designed for real-time inference, process this data to generate personalized recommendations or content rankings in mere milliseconds. These predictions are then seamlessly integrated into the user interface using technologies like WebSockets, enabling immediate updates that feel smooth and natural.
For the long haul, scalable databases store user profiles and content catalogs, while monitoring tools keep an eye on performance metrics to maintain low latency and quickly detect any issues. Auto-scaling systems also play a critical role, allowing the infrastructure to adapt to traffic surges without compromising response times. Together, these elements form a powerful framework for delivering tailored, real-time experiences to users.
SurferCloud prioritizes your data's privacy and security during AI-powered personalization by operating entirely within its private cloud infrastructure. All AI models and data are managed on dedicated compute nodes, eliminating reliance on external services and ensuring sensitive user information remains under your control.
To bolster security, SurferCloud employs sandboxed virtual environments equipped with firewalls, detailed access controls, and optional private networking. Key protections include encryption both at rest and in transit, network isolation, and DDoS mitigation. These safeguards not only comply with regulations like GDPR and CCPA but also help businesses deliver real-time personalization while adhering to strict U.S. privacy standards and maintaining data within preferred jurisdictions.





