Ultimate Guide To Cache Hit Rate Optimization
Want faster website performance and lower costs? Start ...







Feature engineering pipelines automate transforming raw data into ML-ready features. Using cloud infrastructure improves scalability, speeds up processing, and reduces costs. Here's why this matters:
Cloud services like SurferCloud simplify building these pipelines with elastic compute servers, distributed storage, and global data centers. By focusing on efficient resource use, monitoring, and secure operations, cloud-based pipelines deliver reliable and fast results for modern ML workflows.
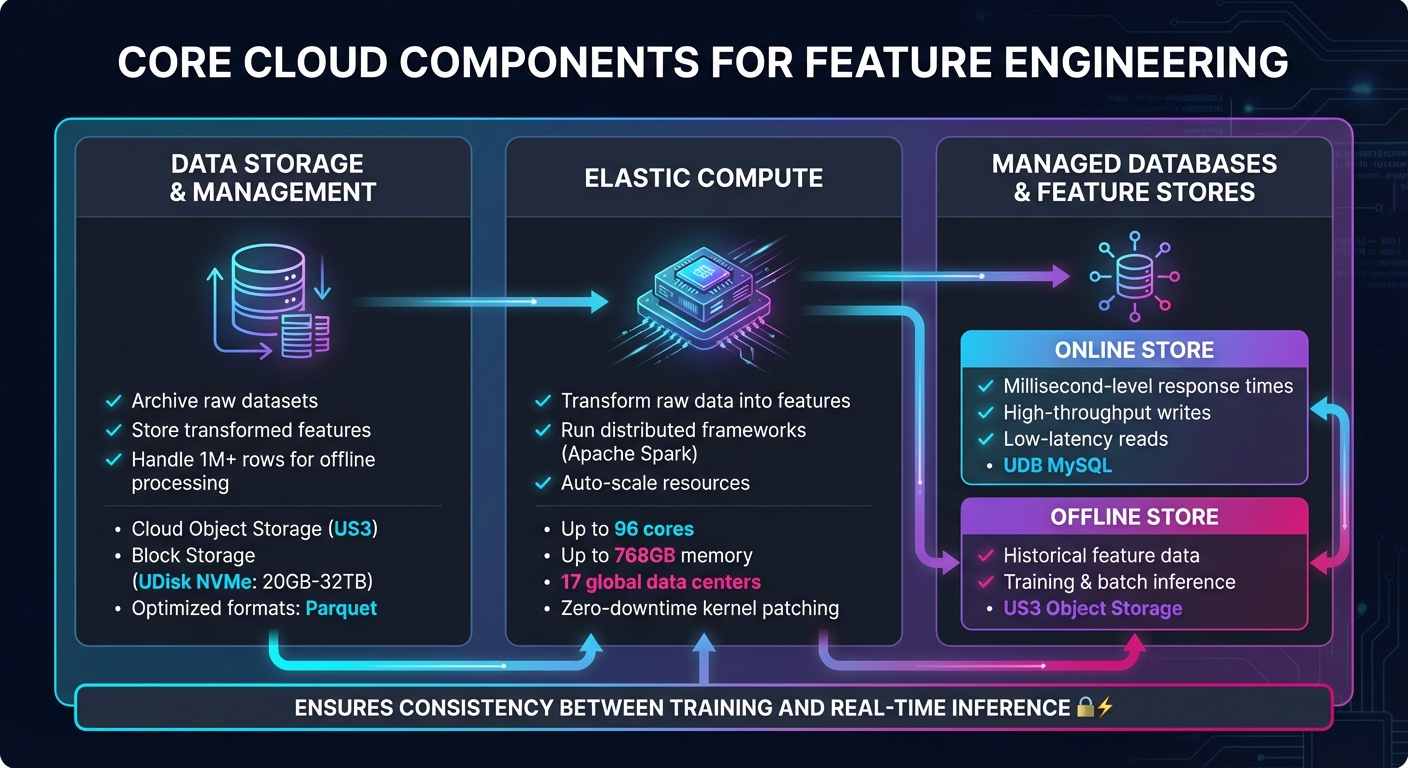
Cloud Components for Feature Engineering Pipelines Architecture
Feature engineering pipelines rely on three key cloud services: cloud storage, elastic compute, and managed databases. These components work together to handle everything from storing raw and processed data to running large-scale transformations and supporting both real-time and historical data needs. Let’s dive into how each of these pieces contributes to scalable feature engineering.
Cloud object storage plays a dual role: it archives raw datasets and stores transformed features. Optimized formats like Parquet are commonly used here, as they improve query performance during processes like model training and batch inference. With this setup, pipelines can handle massive data loads, often exceeding a million rows, for offline storage and processing [3].
SurferCloud offers two storage solutions tailored to these needs:
This combination ensures a cost-effective balance between long-term archival storage and fast, operational storage, making it easier to manage data efficiently within machine learning pipelines.
Transforming raw data into usable features requires significant compute power. Managed compute services, like those running distributed frameworks such as Apache Spark, simplify this process. These services handle infrastructure setup, allowing data scientists to focus on tasks like calculating time-window aggregates or tracking product views, rather than managing servers [1][5].
SurferCloud’s elastic compute servers are built for this kind of heavy lifting:
Feature stores rely on two distinct types of databases:
SurferCloud’s database solutions align perfectly with these requirements:
This separation ensures consistency between training and real-time inference, avoiding the risk of training-serving skew. Additionally, SurferCloud’s Virtual Private Cloud (VPC) offers a secure, isolated network environment, complete with 99.95% availability and built-in DDoS protection, making it suitable for sensitive feature data [6].
| Component | Primary Function | SurferCloud Service |
|---|---|---|
| Offline Store | Historical data storage for training and batch inference | US3 Object Storage |
| Online Store | Low-latency retrieval for real-time inference | UDB MySQL |
| Elastic Compute | Data transformation and feature extraction | Elastic Compute Servers (UHost) |
| High-Performance Storage | Intensive transformation tasks | UDisk Block Storage (NVMe) |
Once your cloud infrastructure is in place, the next step is to fine-tune it for maximum efficiency. This involves scaling resources dynamically, distributing workloads effectively, and keeping a close eye on pipeline health. These strategies not only improve reliability but also help manage costs. Let’s dive into how to make the most of specific cloud features like auto scaling.
Auto scaling is all about adjusting compute resources to match workload demands, keeping costs under control. It can work in two main ways: horizontal autoscaling, which adds or removes worker VMs as needed, and dynamic thread scaling, which optimizes CPU usage for each worker [8].
"SageMaker AI automatically provisions, scales, and shuts down the pipeline orchestration compute resources as your ML workload demands." - Amazon SageMaker AI [7]
For batch pipelines without strict time constraints, Flexible Resource Scheduling (FlexRS) offers a cost-effective solution by combining preemptible and standard VMs [8]. Platforms like SurferCloud provide elastic compute servers that adjust dynamically to workload variations [6]. To avoid unexpected expenses during data surges, always set a maximum worker limit [8]. For streaming pipelines, using dedicated streaming services can improve autoscaling responsiveness and reduce the load on worker VMs [8][10].
Scaling resources is just one part of the equation. Distributing workloads across multiple machines takes performance to the next level.
Distributed processing frameworks, like Apache Spark, are game-changers when working with large datasets. They speed up feature transformations by splitting data across machines. For massive datasets, you can use macrosharding to divide data across machines or microsharding to split data across multiple vCPU threads on a single machine [9]. Pairing Spark with GPUs can lead to even greater performance gains - up to 43 times faster compared to CPU-based pipelines [12].
For example, in 2020, Adobe Intelligent Services upgraded their intelligent email service by adopting a GPU-accelerated Spark 3.0 and XGBoost setup. This shift resulted in a 7x performance boost while slashing costs by 90% [12]. Similarly, Verizon Media optimized their customer churn prediction pipeline using a GPU-based Spark ML setup, achieving a 3x speed improvement [12].
Running jobs in the same region as your data storage can cut down on latency and eliminate cross-region data transfer charges [8]. For datasets with interdependent files, full replication ensures all necessary data is on the same instance, streamlining processing [9].
Keeping an eye on data quality is essential for maintaining reliable pipelines. Instead of discarding problematic data, use dead-letter queues to store failed elements separately for later analysis [11].
"Dead-letter queues... catch exceptions in the DoFn.ProcessElement method and log errors. Instead of dropping the failed element, use branching outputs to write failed elements into a separate PCollection object." - Google Cloud Documentation [11]
ML lineage tracking is another useful tool - it helps trace features back to their original data sources, making it easier to pinpoint issues [7][1]. Real-time monitoring can also be enhanced with custom counters to flag specific problems like malformed JSON or missing payloads [11]. For streaming pipelines, set up alerts for data freshness and latency to catch potential delays early. Some cloud environments retry failed work indefinitely, which can lead to stalled pipelines and unexpected charges [10].
SurferCloud’s Virtual Private Cloud (VPC) ensures 99.95% availability and includes built-in DDoS protection, offering peace of mind for critical data pipelines [6]. To prepare for outages, use state snapshots to back up your pipeline’s state, enabling quick recovery [10]. For added resilience, store data in multi-region buckets so pipelines can restart in a healthy region if one goes down [10].
When paired with scalable and distributed systems, robust monitoring ensures your feature engineering pipelines remain efficient and dependable.

Take advantage of SurferCloud's extensive infrastructure to design and implement feature engineering pipelines tailored to your needs. With over 17 global data centers, including multiple locations in the U.S., SurferCloud ensures compliance with data residency requirements while delivering low-latency performance for your applications.
Moving from prototyping to production is seamless with modular, version-controlled workflows [4]. For batch pipelines, you can configure SurferCloud's elastic compute servers to run Apache Spark clusters, enabling distributed feature transformations. Store processed features in Parquet format on cloud storage to make use of efficient column pruning and predicate pushdown [4]. This setup is ideal for offline storage, supporting training workloads effectively.
Real-time pipelines, on the other hand, require a different strategy. Implement a dual-serving approach by using SurferCloud's managed databases as an online store for millisecond-latency reads during inference, while maintaining a Parquet-based offline store for batch training [4]. To manage task dependencies, self-host Apache Airflow on a SurferCloud VPS and define Directed Acyclic Graphs (DAGs). Handle late-arriving data with event-time processing and watermarking to strike a balance between timeliness and data completeness [4].
Optimize incremental updates with carefully designed read policies to minimize reprocessing costs [4]. By hosting pipelines near your primary data sources using SurferCloud's data center switching, you can further reduce network latency.
Once your architecture is in place, efficient resource management becomes critical for keeping costs under control.
To manage costs effectively, start by profiling your code to identify bottlenecks, then adjust SurferCloud's customizable VPS resources to scale CPU and RAM as needed for compute-heavy tasks. During storage phases, downscale resources to save money [4]. For batch jobs, consider using preemptible instances, which can significantly reduce costs and typically last up to 24 hours [15].
Cut unnecessary processing and storage expenses by eliminating irrelevant data early in your pipelines [4]. Avoid costly operations like groupBy on non-partition keys, as these can lead to expensive data shuffles across clusters [4]. Enable autoscaling on node pools so you only pay for resources in active use [15]. Regularly clean up unused feature groups, temporary storage buckets, and idle instances to avoid unnecessary charges [3].
Adopt a storage tiering strategy that aligns with your access patterns. Use your online store for high-throughput, real-time inference, while relying on cost-efficient S3-compatible buckets for historical data and batch training [3]. For pipelines handling large datasets - think 1 million rows or more - this dual-store setup balances performance with cost efficiency [3].
While cost management is essential, securing your pipelines is just as important.
SurferCloud's Virtual Private Cloud (VPC) provides built-in DDoS protection and secure networking. Use the customer portal to configure security groups, allowlist specific IPs, and enforce SSH key-based access for all servers. Deploy pipelines in regional data centers to meet U.S. data residency requirements while ensuring high availability across multiple Availability Zones [3].
Implement Role-Based Access Control (RBAC) to limit access to sensitive feature sets and pipeline configurations [1][14]. Refrain from including Personally Identifiable Information (PII) in feature group names, descriptions, or metadata tags [3]. Maintain ML lineage tracking to trace features back to their raw data sources, which is essential for debugging, reproducibility, and meeting regulatory requirements [14][16].
Versioned snapshots of datasets ensure that models train on consistent data, which is particularly useful during compliance audits [16]. Encrypt data both at rest and in transit, and integrate pipelines with CI/CD tools like GitHub Actions to automate deployments with consistent testing [13]. Centralized logging is also key - it allows you to monitor both active and terminated pipelines, helping you quickly identify performance issues or security incidents [15].
Cloud infrastructure offers a game-changing combination of scalability, cost efficiency, and reliability compared to traditional on-premises systems. Managed feature stores play a critical role by aligning data processing for both training and inference, eliminating inconsistencies like skew[3]. Plus, the ability to handle massive data batches - think 1 million rows or more - lays the groundwork for robust, production-ready machine learning workflows.
The financial perks are hard to ignore. Teams can reuse features across projects, slashing redundant workloads[3]. Add to that resource optimization, where you only pay for the compute power you actually use[2]. Distributed processing across Availability Zones ensures high availability, while online feature stores deliver predictions in milliseconds, perfect for real-time applications[3]. Together, these advantages make cloud-based pipelines a strategic win.
For U.S.-based organizations, SurferCloud’s network of 17+ global data centers - including several within the U.S. - offers a secure and scalable infrastructure. This setup not only streamlines workflows but also satisfies U.S. data residency requirements. With elastic compute servers, managed databases, and VPC networking, the platform supports both batch and real-time pipelines - all without the hassle of managing physical infrastructure.
Security and compliance are baked into the system. Automated lineage tracking, granular access controls, and encryption ensure that pipelines remain secure and auditable as your operations grow[1]. These features make scaling seamless while keeping your data safe and your processes transparent.
Cloud infrastructure revolutionizes feature engineering pipelines by providing scalable, on-demand resources and removing the hassle of managing servers manually. With the ability to instantly provision compute power, storage, and networking, pipelines can adapt to handle everything from a few gigabytes to massive terabytes of data without any slowdowns or bottlenecks.
SurferCloud takes this a step further with its elastic compute servers and high-performance cloud storage. Operating across more than 17 global data centers, it enables organizations to quickly set up large-scale processing clusters when needed and shut them down just as easily, keeping costs under control. Integrated tools like networking, CDN, and database solutions ensure smooth and fast data transitions between different stages of the pipeline. Plus, with built-in security features and 24/7 expert support, teams can trust the system to handle surges in data or training demands without worrying about infrastructure constraints.
Elastic compute servers simplify data transformation by automatically adjusting and scaling computing power to match the demands of your workload. This dynamic allocation means tasks are processed faster and more efficiently, thanks to the ability to use multiple virtual CPUs (vCPUs) to handle large-scale data operations effortlessly.
These servers align with your workflow requirements, ensuring resources are used effectively, costs are minimized, and performance remains steady. This makes them an essential tool for building scalable and reliable feature engineering pipelines.
SurferCloud takes data security and regulatory compliance seriously, especially when it comes to feature engineering pipelines. The platform uses robust encryption to protect data both at rest and in transit, ensuring sensitive information remains secure. On top of that, strict role-based access controls are enforced, adhering to the principle of least privilege. This means only authorized users can access critical data. To keep everything in check, SurferCloud conducts regular audits and uses automated compliance checks to help businesses align with regulations like HIPAA and GDPR.
Security is woven into every stage of the feature engineering workflow, from initial design to final deployment. Tools such as secure compute isolation, detailed logging, and automated vulnerability scanning are built into the platform, ensuring data integrity and traceability. Fine-grained access controls further ensure that sensitive feature data stays protected within a secure, customer-controlled environment.
SurferCloud also integrates services like elastic compute servers and managed storage to support large-scale feature engineering projects. By combining advanced encryption, secure networking, and managed secret handling, the platform allows data scientists to focus on their work with confidence, knowing that security and compliance are never compromised.

Want faster website performance and lower costs? Start ...
Introduction: The Changing Landscape of Cloud Hosting i...
As data grows, traditional relational databases can’t...





