Why SurferCloud is the Best Cloud PC Alternat
Why Your Current Cloud PC Provider Might Be Failing You...







Differential privacy is a mathematical method that protects individual data in AI systems by adding controlled noise during training. This ensures that AI models can analyze data patterns without revealing sensitive personal information. It's already used by companies like Google and Apple, as well as in government projects like the U.S. Census. Implementing it effectively requires balancing privacy and model accuracy, which depends on parameters like epsilon (ε) and delta (δ). Cloud platforms, such as SurferCloud, simplify this process with tools for secure training and privacy monitoring. While differential privacy enhances security, it can impact model performance, especially with smaller datasets or strict privacy settings.
Differential privacy is a rigorous mathematical framework designed to protect individual privacy while still allowing for meaningful statistical analysis of data [1]. At its core, it ensures that an AI model's output remains virtually unchanged, regardless of whether any specific individual's data is included in the dataset. This makes it particularly valuable for training AI models that rely on large datasets containing sensitive information, such as deep neural networks, without compromising personal privacy [7]. Cynthia Dwork captures the essence of this concept:
"The intuition for the definition of ε-differential privacy is that a person's privacy cannot be compromised by a statistical release if their data are not in the database" [1].
The framework operates using two main parameters: epsilon (ε) and delta (δ). Epsilon represents the "privacy loss budget", or how much privacy is sacrificed, while delta indicates the likelihood of a privacy breach [1][5]. Smaller epsilon values mean stronger privacy protection but can reduce the utility of the data. For example, Google Research suggests that ε ≤ 1 provides robust privacy, while ε values up to 10 are often considered a reasonable balance for machine learning tasks [2]. To achieve these privacy guarantees, differential privacy employs a noise injection mechanism.
Differential privacy relies on adding carefully calibrated random noise to the results of computations. The amount of noise depends on the "sensitivity" of the function being analyzed - essentially, the maximum impact that a single individual's data could have on the output [1]. Functions with higher sensitivity require more noise to maintain the same level of privacy.
Two main noise mechanisms are commonly used:
In practice, methods like Differentially Private Stochastic Gradient Descent (DP-SGD) implement these principles by clipping individual gradients to a fixed maximum norm and then adding random noise to the aggregated gradients before updating the model's weights [2].
One of the standout strengths of differential privacy is its post-processing robustness. Once a result is made differentially private, any further mathematical operations or transformations cannot increase the privacy risk [1]. This makes it particularly useful in cloud-based AI systems, where data often undergoes multiple stages of processing.
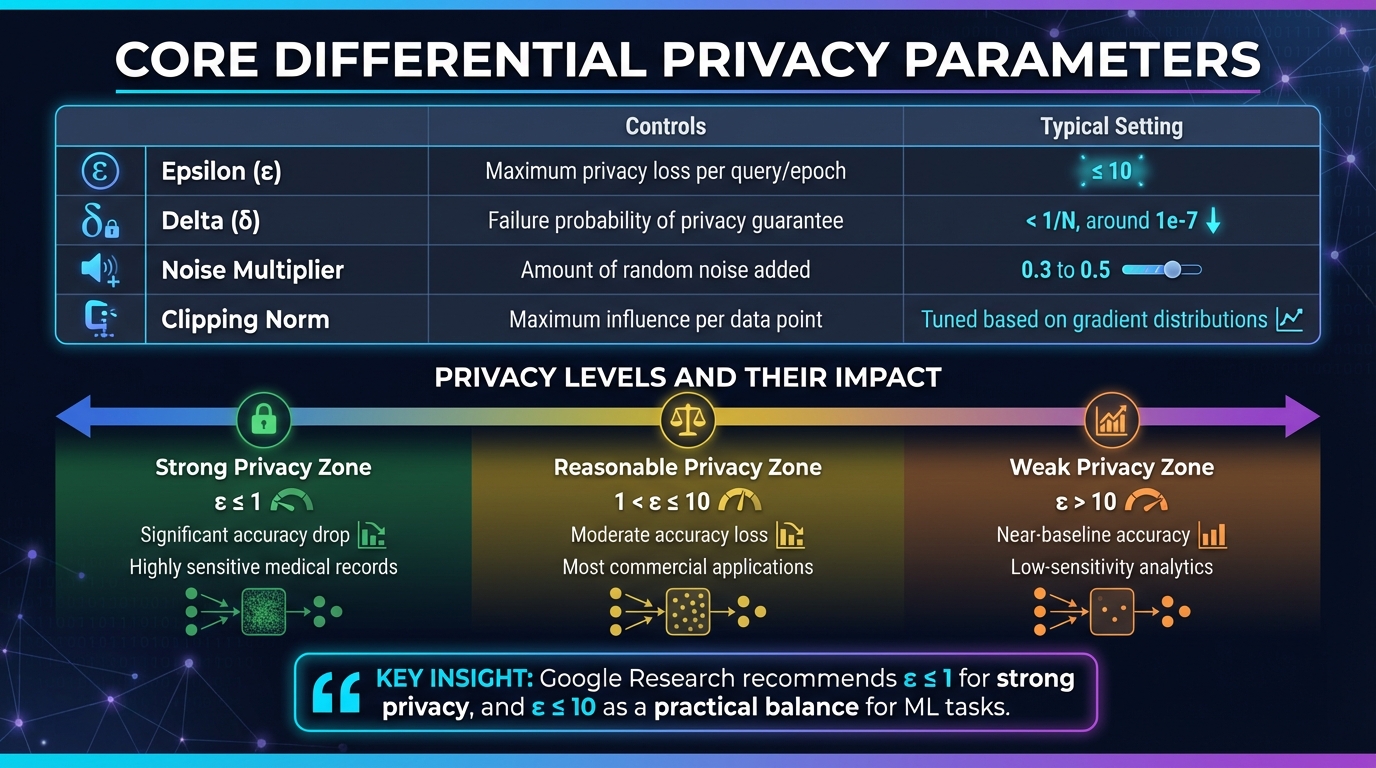
Differential Privacy Parameters and Trade-offs in Cloud AI
Differential privacy in cloud AI revolves around managing a privacy budget, which ensures that individual data contributions remain secure. This budget is defined by two critical parameters: epsilon (ε) and delta (δ). These parameters work together to control how much information about a single individual can be inferred.
"Choosing ε ≤ 1 provides a strong privacy guarantee, but frequently results in a significant utility drop for large models." [2]
To strike a balance between privacy and performance, teams often set ε to around 10.
Another essential mechanism is gradient clipping, which limits how much any single data point can influence the model. This is combined with a noise multiplier, which determines the amount of random noise injected into the training process. Typically, using noise multipliers between 0.3 and 0.5 results in ε values close to 10.
Here’s a snapshot of how these parameters are typically configured in cloud AI systems:
| Parameter | What It Controls | Typical Cloud AI Setting |
|---|---|---|
| Epsilon (ε) | Maximum privacy loss per query/epoch | Generally ≤ 10 |
| Delta (δ) | Failure probability of the privacy guarantee | Often set to < 1/N, around 1e-7 |
| Noise Multiplier | Amount of random noise added | Typically between 0.3 and 0.5 |
| Clipping Norm | Maximum influence per data point | Tuned based on gradient distributions |
These parameters lay the groundwork for implementing differential privacy effectively.
To apply differential privacy, many teams use Differentially Private Stochastic Gradient Descent (DP-SGD). This method ensures privacy by systematically introducing noise into the training process. Here's how it works:
Tools like TensorFlow's privacy utilities can even calculate the (ε, δ) cost in advance, helping teams avoid unexpected budget exhaustion.
Differential privacy brings some solid advantages to cloud-based AI systems. For starters, it complies with privacy-by-design standards outlined in regulations like GDPR, CCPA, and HIPAA. This framework is particularly effective in preventing re-identification, even when targeted attacks are involved. For example, it safeguards against differencing attacks, where bad actors attempt to isolate individual records by issuing multiple queries [5].
Another standout feature is its ability to facilitate secure collaboration across sectors like finance and healthcare. With differential privacy, multiple parties can train models together without ever exposing their raw data. This has been proven effective in real-world scenarios.
From a cost standpoint, it’s worth noting that providers like Google BigQuery include differential privacy features without adding extra charges - users only pay for regular data analysis services [3][6].
However, while the benefits are clear, there are trade-offs that organizations need to navigate carefully.
One of the biggest challenges with differential privacy is the privacy-utility trade-off. Lowering the epsilon (ε) value enhances privacy but can significantly impact model accuracy. Additionally, the noise added to protect data slows training times and increases memory usage [2][8]. For instance, when ε is set to 1 or below to ensure strong privacy, models often suffer noticeable accuracy drops. This is why practical applications typically aim for ε values up to 10, striking a balance between privacy and usability. In one experiment involving a pneumonia chest X-ray dataset, training with DP-SGD took 109 seconds per epoch, compared to faster non-private training [8].
Cloud data warehouses also face slower query execution due to the extra steps involved, such as per-entity aggregation and contribution limiting [6].
Smaller datasets come with their own set of issues, as the added noise can overwhelm the signal, leading to distorted results. To counter this, explicit clamping is often required [6].
| Privacy Level | Epsilon (ε) Value | Model Accuracy Impact | Use Case |
|---|---|---|---|
| Strong | ε ≤ 1 | Significant accuracy drop | Highly sensitive medical records |
| Reasonable | 1 < ε ≤ 10 | Moderate accuracy loss | Most commercial applications |
| Weak | ε > 10 | Near-baseline accuracy | Low-sensitivity analytics |
Another critical factor is the cumulative nature of the privacy budget. Each query or training iteration consumes part of this budget, and once it’s exhausted, further queries are blocked until it resets. This requires organizations to closely monitor privacy loss to ensure uninterrupted service while maintaining robust data protection guarantees.
SurferCloud builds on the concepts of noise injection and privacy budgeting to provide a robust infrastructure for implementing differential privacy in AI workflows.
SurferCloud offers a range of tools to integrate differential privacy into your AI processes. Its GPU UHost instances handle demanding tasks like gradient clipping and noise injection during model training. Meanwhile, UModelVerse supports popular frameworks like PyTorch and vLLM, making it easy to deploy open-source models such as Llama 3 or Mistral. To enhance security, this setup blocks third-party logging, ensuring model weights remain protected.
To reduce the trade-off between privacy and model performance, consider using larger batch sizes or employing gradient accumulation. As Natalia Ponomareva and Alex Kurakin from Google Research explain:
"The utility of DP‐trained models is sensitive to the total amount of noise added, which depends on hyperparameters, like the clipping norm and batch size."
Because per-example clipping increases memory demands, it’s wise to use GPU instances with high VRAM or apply ghost clipping techniques. For most applications, ε values up to 10 strike a practical balance between usability and privacy [2].
For data management, US3 provides unlimited object storage for training datasets, while UDB handles structured data with automated backups for MySQL, MongoDB, and PostgreSQL. To secure sensitive training data, UNet allows you to create isolated VPCs. Additionally, implementing a privacy budget monitor helps track cumulative loss and manage training iterations effectively.
These tools and configurations support scalable, privacy-focused AI workflows.
SurferCloud goes beyond configuration to ensure seamless scaling and adherence to regulatory standards.
With 17+ data centers worldwide, SurferCloud enables compliance with regional data residency laws while supporting differential privacy. For instance, you can deploy resources in Frankfurt or London to meet GDPR requirements or in Singapore or Tokyo for reduced latency in the Asia-Pacific region.
The platform guarantees 99.95% availability and uses kernel hot patch technology, allowing continuous monitoring without the need to restart cloud hosts. This is especially important for maintaining audit trails during regulatory reviews [4]. For large-scale training that surpasses single-server memory limits, UK8S (managed Kubernetes) coordinates clusters across multiple nodes. Tools like PipelineDP can handle complex differential privacy queries in minutes when deployed on elastic cloud infrastructure [9].
SurferCloud also prioritizes privacy-centric features, such as a no KYC policy and support for USDT payments, offering operational privacy for organizations working on sensitive AI research. Around-the-clock technical support ensures compliance during security incidents or scaling challenges. With Tier 3 data center standards, host intrusion detection, and DDoS protection, SurferCloud provides a secure foundation for privacy-preserving AI workflows as you scale [4].
Differential privacy has reshaped how cloud AI systems approach security by offering mathematically-backed methods to safeguard data. This technique has already gained the trust of major industry players - Google began using it in 2014, Apple followed in 2016, and the U.S. Census Bureau applied it during the 2020 Census to balance data utility with privacy protections [1].
By introducing carefully calibrated noise and monitoring privacy loss with ε, differential privacy enables organizations to extract insights from sensitive data while ensuring individual privacy. However, its success hinges on the right infrastructure. SurferCloud's GPU-accelerated instances make tasks like gradient clipping and noise injection more efficient, while their 17+ global data centers help meet regional data residency requirements. Additional features, such as the absence of KYC requirements and support for USDT payments, add another layer of operational privacy.
Integrating differential privacy into AI workflows requires fine-tuning hyperparameters like batch size and learning rate to account for the added noise. The right infrastructure - like what SurferCloud provides - can simplify these adjustments. For instance, Google Research suggests using ε ≤ 1 for robust privacy and ε ≤ 10 as a practical benchmark for most machine learning models [2]. By combining rigorous mathematical principles with reliable cloud infrastructure, organizations can develop AI systems that protect user privacy without compromising performance.
Differential privacy is a method designed to safeguard sensitive data during AI model training. By introducing carefully controlled random noise to either the data itself or the model updates, it ensures that individual data points remain private while the model continues to detect meaningful patterns.
A key element in this process is the ε (epsilon) parameter, which helps strike a balance between privacy and accuracy. A smaller ε means stronger privacy protection, as it introduces more noise, but this can come at the cost of reduced model accuracy. On the other hand, a larger ε allows for higher accuracy by minimizing noise, though it compromises privacy to some extent. This flexibility lets organizations adjust the privacy settings to fit their unique requirements.
Implementing differential privacy (DP) in cloud-based AI systems isn’t without its hurdles. One major challenge lies in striking the right balance between privacy and model performance. To protect sensitive data, random noise is added, but this can come at the cost of reduced model accuracy. Fine-tuning the privacy budget (ε) becomes crucial to maintain both data protection and the model's utility.
Another issue is the increased computational load that DP mechanisms introduce. These processes can slow down training times and demand more memory, especially when operating at cloud scale. On top of that, managing the privacy budget - which tracks cumulative privacy loss across multiple operations - requires advanced tools to ensure compliance with privacy regulations.
SurferCloud addresses these challenges head-on by offering secure and scalable resources tailored for DP-heavy workloads. With their expert support, businesses can streamline tasks like tuning and monitoring, making it easier to develop high-performing AI models while safeguarding sensitive data.
Fine-tuning differential privacy (DP) settings is all about finding the right balance between protecting sensitive data and keeping your AI model accurate. The process begins with choosing a suitable privacy budget - typically represented as ε and δ - that meets your organization's regulatory and operational needs. This step is critical to safeguarding private information while still extracting useful insights. From there, tweaking parameters like noise levels, gradient clipping thresholds, and batch sizes can help boost model performance without undermining privacy.
When working in a cloud-based AI environment, built-in DP tools can make this process much smoother. These tools often handle tasks like noise calibration, monitoring privacy loss, and enabling real-time adjustments to maintain compliance with privacy regulations. For instance, platforms such as SurferCloud offer scalable solutions designed for DP-optimized workflows, making it easier to train and deploy AI models that prioritize data privacy on a large scale.





