Pay-As-You-Go vs. Reserved Pricing in Multi-C
When choosing between Pay-As-You-Go (PAYG) and Reserved...






Multi-region SLA compliance ensures your cloud infrastructure meets service-level agreements (SLAs) across multiple geographic regions. This approach tackles challenges like availability, latency, and recovery targets while adhering to regulations like data residency laws. Here's what you need to know:
Key takeaway: Multi-region SLA compliance requires careful planning, redundancy, and monitoring to balance cost and reliability while meeting legal and operational requirements.
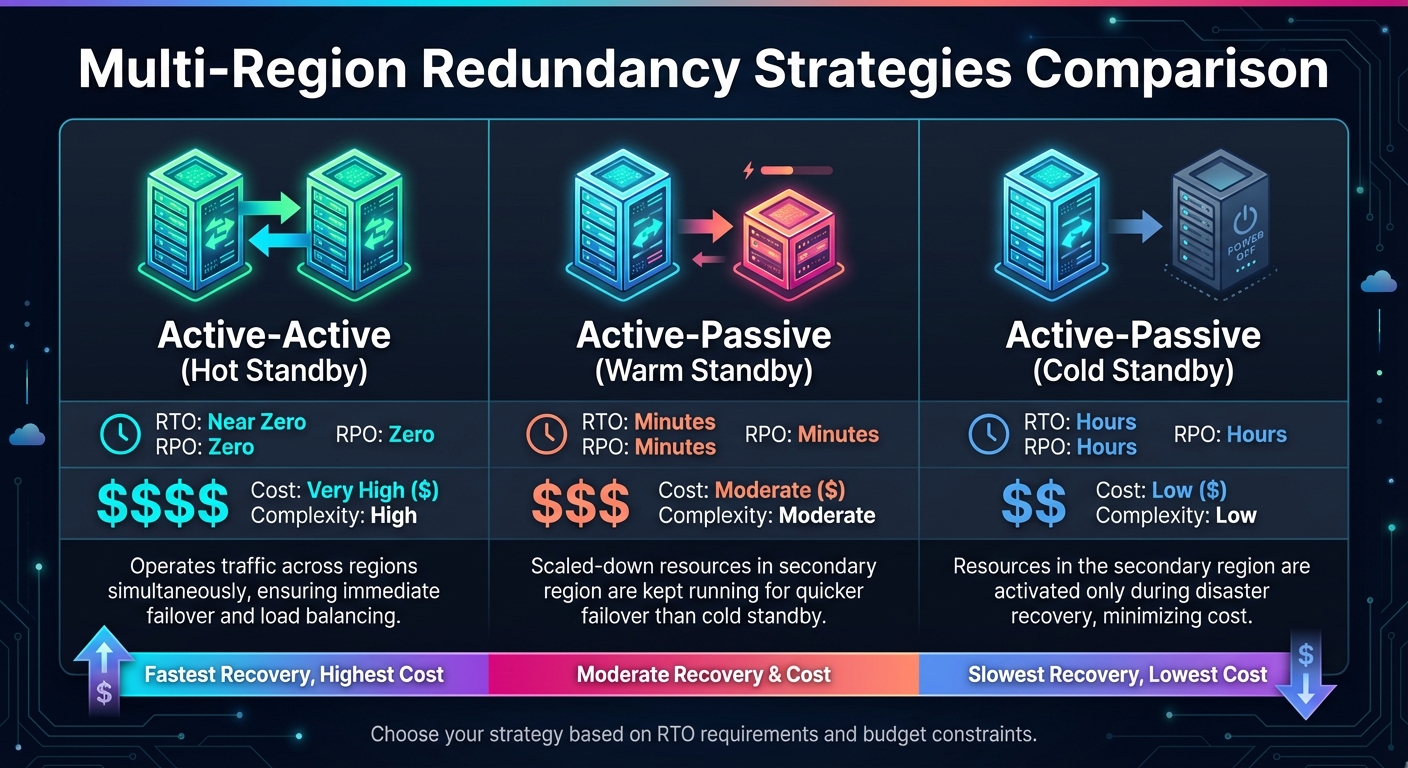
Multi-Region Redundancy Strategies: RTO, RPO, Cost and Complexity Comparison
Before deployment, it's essential to map out the specific business and regulatory requirements for each region. Begin with a Business Impact Analysis (BIA) to establish clear Recovery Time Objective (RTO) and Recovery Point Objective (RPO) metrics tailored to each workload [5]. Categorize applications into tiers based on their importance to help manage costs and complexity effectively [3].
Regional data residency laws play a significant role in determining where data must physically reside and how it can be replicated. While synchronous replication ensures no data loss, it can increase latency. On the other hand, asynchronous replication offers lower latency but carries a slight risk of data loss during failover [1]. Discuss these trade-offs with stakeholders early, as implementing a multi-region "hot standby" setup can double infrastructure and operational costs compared to a single-region approach [3].
Consistency across regions is key. Configure security controls, Identity and Access Management (IAM) policies, and firewalls uniformly to maintain compliance during failovers [5]. Additionally, apply resource locks, such as Azure's "CanNotDelete", to critical assets like DNS zones and data stores to prevent accidental deletions [4].
When planning for availability, Multi-AZ architectures can achieve 99.99% uptime, while multi-region strategies are reserved for scenarios requiring extreme resilience or protection against region-wide failures [6]. The difference between 99.5% and 99.99% availability translates to over 3.5 hours of additional downtime each month [6].
Choose a redundancy strategy that aligns with your RTO and budget:
| Strategy | RTO | RPO | Cost | Complexity |
|---|---|---|---|---|
| Active-Active | Near Zero | Zero | Very High | High |
| Warm Standby | Minutes | Minutes | Moderate | Moderate |
| Cold Standby | Hours | Hours | Low | Low |
To ensure seamless failover, keep the compute layer stateless, allowing individual nodes to be replaced without risking data loss [4]. Opt for serverless or fully managed services that handle replication and failover automatically [4]. Use global load balancers like AWS Global Accelerator or Azure Front Door to route traffic based on health, latency, or weighted rules [6].
Automate failover processes to meet RTO goals, but handle failback manually to ensure data consistency before returning to the primary region. Establish "disaster thresholds" in your monitoring tools to avoid false positives and only trigger failover when a genuine business-impacting issue arises [1].
With redundancy in place, the next step is to fine-tune network performance to meet service-level agreements (SLAs).
Network latency plays a critical role in maintaining SLA compliance. For global SaaS platforms, latency exceeding 200 ms can lead to higher user churn and reduced conversion rates [7]. Set clear latency and throughput benchmarks for each region in line with your SLA commitments.
To reduce latency:
For better performance, consider "Leader Pinning", which ensures partition leaders are located closer to your primary client base. This reduces cross-region write/read latency. Additionally, let consumers fetch data from the nearest replica rather than the leader to cut down on network transfer costs.
Monitor network performance metrics like latency, jitter, packet loss, and throughput using observability tools to ensure they remain within SLA-defined Service Level Objectives (SLOs). To balance consistency and availability, note that synchronous replication can increase write latency. For non-critical data, asynchronous replication may be a better choice. Finally, plan for sufficient bandwidth during peak usage periods to avoid bottlenecks that could breach throughput-related SLAs.
Building a resilient architecture is just the start - keeping it running smoothly requires effective monitoring and reporting. These practices are essential for maintaining regional SLA compliance.
Start by identifying Service Level Indicators (SLIs) that directly reflect the user experience in each region. These should include metrics like availability (uptime percentage), latency (response time), and error rates (percentage of failed requests) [11]. Use percentiles, such as p99, to capture outlier data that could impact performance.
Next, set Service Level Objectives (SLOs) for each SLI. These targets should follow the SMART framework (Specific, Measurable, Achievable, Relevant, and Time-bound). To stay proactive, make your SLOs slightly stricter than your SLA commitments. For example, if your SLA guarantees 99.9% availability, aim for an internal SLO of 99.95%. This way, you can catch and address potential issues before they violate customer agreements. Additionally, calculate error budgets to monitor how much room you have for errors within a given compliance period [8][16].
Use historical data to establish regional baselines, as factors like network conditions and user behavior can vary significantly by geography [12][13]. For API services, a common threshold is to set alarms if 4XX and 5XX errors exceed 5% of total requests, while p90 latency thresholds often start at 2,500 ms [12]. Keep an eye on burn rates to understand how quickly your error budget is being consumed. This helps you act quickly and avoid SLA breaches [9].
These metrics serve as the backbone for effective regional monitoring.
Leverage centralized tools to track metrics, logs, and error rates for each region. Ensure that monitored resources are tagged with specific labels like location, region, or zone to maintain accurate tracking [14]. For disaster recovery setups, monitor LagDuration (average time of lag) and Backlog (data written but not yet replicated) to ensure Recovery Point Objective (RPO) goals are met [10].
Use automated dashboards to consolidate key metrics like replication lag, server counts, and regional incident histories [10][15]. Implement composite alarms that combine short-term (e.g., 5-minute) and long-term (e.g., 1-hour) monitoring windows. This dual approach helps detect both sudden spikes and gradual trends while reducing unnecessary alerts [9]. Additionally, track Route 53 health checks, focusing on the "HealthCheckPercentageHealthy" metric to monitor endpoint health [11]. Set exclusions for scheduled maintenance periods to prevent false alarms or unnecessary hits to your error budget [9].
Once your monitoring tools are in place, the next step is to ensure clear reporting and alerting systems.
Design dashboards tailored to different needs: User experience, Business metrics, and Operational performance [11]. Calculate availability using this formula:
100 * ((Total Requests - 4XX Errors - 5XX Errors) / Total Requests) [11]. A 28-day reporting window is a good starting point, balancing immediate alerts with long-term insights [13].
Integrate monitoring tools with Amazon SNS or EventBridge to send real-time alerts for critical issues like replication stalls or high burn rates [10]. Set up thresholds that trigger alerts only when multiple metrics - such as latency and availability - are breached simultaneously. This reduces unnecessary noise [11]. To document SLA compliance, ensure your reporting systems capture detailed server logs, including the date, time, and duration of any external connectivity issues [17]. Use cost allocation tags to track expenses for cross-region redundancy, helping you manage disaster recovery budgets efficiently [10].
Having clear documentation and governance in place is crucial for staying on top of SLA compliance. Without well-defined contracts, clear roles, and proper audit trails, even the most advanced monitoring systems can fall short - especially when regional regulations change or disputes arise. Building on monitoring and design best practices, strong documentation and governance help ensure SLA compliance remains consistent.
SLA contracts must clearly outline regional coverage and any exclusions. Start by specifying the territory and jurisdiction for each agreement, detailing the regions covered and the legal frameworks that apply [18][21]. This is especially important for compliance with data residency laws like GDPR (EU), LGPD (Brazil), or PDPA (Singapore), which often require data to remain within specific geographic boundaries [21].
Define Service Level Objectives (SLOs) for each region, including specific uptime percentages. For example, a Platinum resilience tier typically guarantees 99.99% availability, which translates to just 52.60 minutes of allowable downtime annually [3]. Include Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) for workloads [3]. Some cloud providers, for instance, offer a Monthly Uptime Percentage of ≥99.95% for standard storage in multi-region deployments, though this can vary depending on the region [19].
Clarify how failover and redundancy affect availability metrics. If a regional failover occurs, specify whether service credits apply during the transition [3][19]. Financial credits are often tiered based on uptime performance, with a maximum cap of 50% of the monthly bill in most cases [19]. Also, explicitly list exclusions, such as regional ISP outages or latency caused by external network issues, as these are typically outside the provider's control [19][21].
Clear contract terms are only effective if supported by strong governance. Establish a dedicated governance structure to oversee SLA compliance. This could include an architectural review board and CloudOps teams responsible for monitoring service levels and generating reports [22]. Collaboration is key - business teams should define objectives, while technical teams provide realistic estimates based on system limitations [8].
"Config management only clicks when your people and playbooks are in sync... If they're not all looking at the same config data and escalation matrix, you'll spend more time firefighting than automating."
– Anna, ITAM expert at Cloudaware [20]
Assign clear roles and responsibilities. For instance, a Configuration Manager can oversee the Configuration Management Database (CMDB) to ensure all changes comply with regional terms [20]. Combine this with ongoing governance practices to regularly review and align with regional SLA requirements. Schedule periodic reviews of SLOs and SLAs - quarterly or semi-annually - to ensure they remain relevant as your systems and business goals evolve [8][18]. Use configuration management tools to embed regional compliance rules, such as encryption standards and logging requirements, directly into the technical specifications of your contracts [20].
Maintain detailed monitoring records to support audit verification. Documentation should include server log files that capture connectivity issues, error timestamps, and records of who accessed backup data or performed recovery actions [2][17]. These audit trails are vital for demonstrating compliance.
"Teams should define and document Service Level Objectives (SLOs) for every service, regardless of whether it is directly consumed by external customers or used internally."
– AWS [8]
Set up reporting schedules for both internal and external stakeholders. Automate reports ranging from daily to monthly, and share them via public URLs or email to keep everyone informed [23]. For multi-region deployments, include visualizations like latency heatmaps and regional uptime summaries [23]. Ensure disaster recovery environments meet the same security and compliance standards as production systems, including encryption and PII redaction [2]. To claim financial credits for SLA breaches, customers typically need to notify the provider within 30 days and provide server logs as evidence [17].
Anticipate and address potential risks to SLA compliance before unexpected disruptions or regulatory changes impact your operations.
Align your SLA requirements with regional regulations. For instance, data residency and sovereignty laws often require that data at rest remains within specific locations and is processed only within those jurisdictions[24]. Additionally, some regulations may restrict workload access to predefined locations or specific identities, such as domain-restricted sharing[24].
Operational risks can be just as damaging to SLA performance as regulatory issues. Configuration inconsistencies across regions can lead to uneven performance and data gaps[25]. Dependencies across regions - where one component relies on a service in another - can increase the risk of failure and compromise reliability[25]. Encryption requirements, such as customer-managed keys (CSEK) or external key managers (EKM), may also introduce latency or reliability challenges if the key infrastructure lacks high availability[24].
"If you create dependencies between Regions where a component in one Region relies on services or components in a different Region, you can increase the risk of failure and significantly weaken your reliability posture."
– AWS Well-Architected Framework[25]
Conduct Failure Mode Analysis (FMA) to pinpoint potential failure points and cross-region dependencies before they affect SLA performance[26]. For applications aiming for 99.99% availability, downtime must stay under 8.64 seconds per day. This translates to no more than 10 failed requests per 100,000 received[29].
Define a detailed audit scope that includes configuration states, network connections, operating system and application versions, and the specific locations of storage or database resources[28]. Centralize compliance tracking by exporting regional audit logs to a unified archive[2]. Use Infrastructure as Code (IaC) tools like Terraform to standardize IAM policies, network setups, and security controls across all regions, minimizing security vulnerabilities[2].
Create a responsibility matrix (RACI) to clearly outline roles during incidents, such as SLA breaches or disasters[28]. Keep offline copies of architecture diagrams, vendor contact details, and recovery procedures[28]. Ensure all systems in the failover region are fully operational before declaring recovery a success[28].
"A DR plan is only meaningful when validated under realistic conditions. Test multiple scenarios, including edge cases, and combine scheduled drills with surprise game days."
– Microsoft Azure Well-Architected Framework[1]
Schedule regular disaster recovery drills to build team readiness and uncover gaps caused by system changes over time[28]. While automation can speed up recovery, add manual approval checkpoints for high-risk actions like regional failovers to avoid unnecessary disruptions caused by false positives[1]. Confirm that the secondary region has enough reserved or pre-allocated resources to handle full production loads during a failover[2].
These audits lay the groundwork for proactive risk management in multi-region environments.
Expand on audit insights by continuously monitoring and addressing risks. Maintain a risk register to document threats, past incidents, and lessons learned[28]. Develop a remediation backlog for SLA gaps, prioritizing tasks based on the likelihood and impact of events like cloud region outages or service degradation[27]. Use logs, metrics, and traces to gain real-time visibility into system health and catch potential SLA breaches early[22].
Set SMART SLOs (Specific, Measurable, Achievable, Relevant, Time-Bound) to clearly define performance commitments[22]. Ensure that logs collected during a regional failover are backfilled into the primary log archive to maintain a seamless audit trail for compliance[2]. Assign key personnel to declare disasters and rely on automated runbooks to execute failovers efficiently[27][28].
"Disaster might be hard to predict, but how we respond to these types of events should be predictable."
– AWS[28]
Establish dedicated communication channels - like virtual or on-site situation rooms - to keep leadership and stakeholders informed during incidents[28]. Track progress on remediation efforts across regions to systematically close identified gaps.
SurferCloud simplifies risk management with integrated features that streamline tracking and mitigation, ensuring strong multi-region SLA compliance.
Using a checklist for multi-region SLA compliance brings structure and reliability to what could otherwise be a chaotic process. By carefully documenting everything - from specific regional regulations to disaster recovery steps - you create clear accountability and remove confusion during high-pressure situations[30]. This preparation helps avoid costly errors during outages[2].
The results speak for themselves. One software development company that adopted an SLA checklist reported a 25% boost in on-time project delivery and a 40% drop in service-related complaints. Even more impressive, they saw 30% growth in repeat business within just one year[31]. These numbers highlight how organized compliance tracking can directly enhance operational efficiency and customer satisfaction.
Managing multi-region architectures is no small feat. Frequent configuration updates and shifting data sovereignty laws can quickly render old practices ineffective. Regularly reviewing and updating your SLA strategy ensures it stays relevant and up to date with current standards[20][21].
"Having an untested recovery approach is equal to not having a recovery approach."
– AWS Prescriptive Guidance[32]
To meet regional data residency laws in a multi-region SLA setup, start by pinpointing the types of data you manage - whether it's personal, financial, or health-related. Then, map that data to the legal requirements of the regions where it's collected or governed. This step helps clarify where your data needs to be stored and processed.
Next, configure your SurferCloud resources to comply with these regulations. Choose data center locations that align with the required jurisdictions. Use region-specific settings for storage, databases, and compute instances to ensure data stays within the appropriate boundaries. Strengthen this setup by implementing access controls and encryption keys that are restricted to the designated region.
Lastly, make compliance an ongoing process by integrating automated checks into your monitoring and reporting workflows. Regularly audit regional configurations, confirm encryption key locations, and generate reports to show compliance with laws like GDPR or CCPA. These measures help you align your SLA with regional data residency rules while ensuring consistent performance and reliability.
The article doesn't dive into the exact cost differences between Active-Active and Cold Standby redundancy strategies, but the two approaches typically differ significantly in expenses due to their infrastructure needs and how they operate.
Active-Active setups tend to be more expensive because they require multiple systems to run simultaneously. These systems are always active, ensuring constant availability and handling load balancing across the network. On the other hand, Cold Standby strategies are usually more budget-friendly. Secondary systems in this setup stay inactive until they're needed, which helps cut down on ongoing resource consumption.
If your business operates in multi-region cloud environments, it's crucial to weigh these strategies against your SLA requirements, financial constraints, and operational goals.
To keep tabs on SLA compliance across multiple regions, start by pinpointing service-level indicators (SLIs) that match your SLA commitments - things like availability, latency, or error rates. Break these metrics down by region and establish clear, measurable service-level objectives (SLOs), such as 99.9% uptime or latency below 100ms. Document these goals in a checklist and make sure your monitoring tools are set up to track the relevant data for each region.
Leverage SurferCloud’s built-in monitoring tools to centralize data collection by deploying agents in every region. Use dashboards to display real-time metrics like uptime percentages and latency patterns. Set up automated alerts to flag any regional SLO violations, and compile these metrics into a global dashboard for a broader view of SLA performance.
Plan regular reports that summarize regional performance, SLA benchmarks, and any service credits owed. Automate this reporting process with SurferCloud’s API or built-in tools to maintain consistency and ensure audit readiness. Include a summary table highlighting key metrics and any credits, formatted in U.S. dollars (e.g., $2,500 for 99.85% uptime).

When choosing between Pay-As-You-Go (PAYG) and Reserved...
For developers in 2025, choosing the right WordPress ho...
Introduction: Why the World is Moving to Cloud PCs I...





