Managing HA
MySQL high availability is based on Binlog for data synchronization. Customers cannot turn off Binlog, otherwise it will cause high availability anomalies.
Self-repair of High Availability
For high availability instances, there is a HAHealthState monitoring indicator. Under normal circumstances, the value of this indicator is 0. When it is detected that there may be problems with the instance and the normal disaster recovery of the cluster cannot be guaranteed, the value of this indicator will become non-zero, which means high availability anomaly.
When a high availability anomaly occurs and it does not recover automatically, you can try the following steps to repair the high availability of the instance:
-
Check whether the current business is normal, if the business is not normal, please contact technical support
-
If the business is normal, check the disk usage of the high availability standby database. The corresponding monitoring item indicator is HAStandyDBDiskUsage. If the disk usage of the high availability standby database is found to be 100%, try to clean up some Binlog in the Binlog management interface to urgently release space. After the space is released, the high availability status will generally be automatically repaired. After it is normal, upgrade the disk configuration according to the business situation.
-
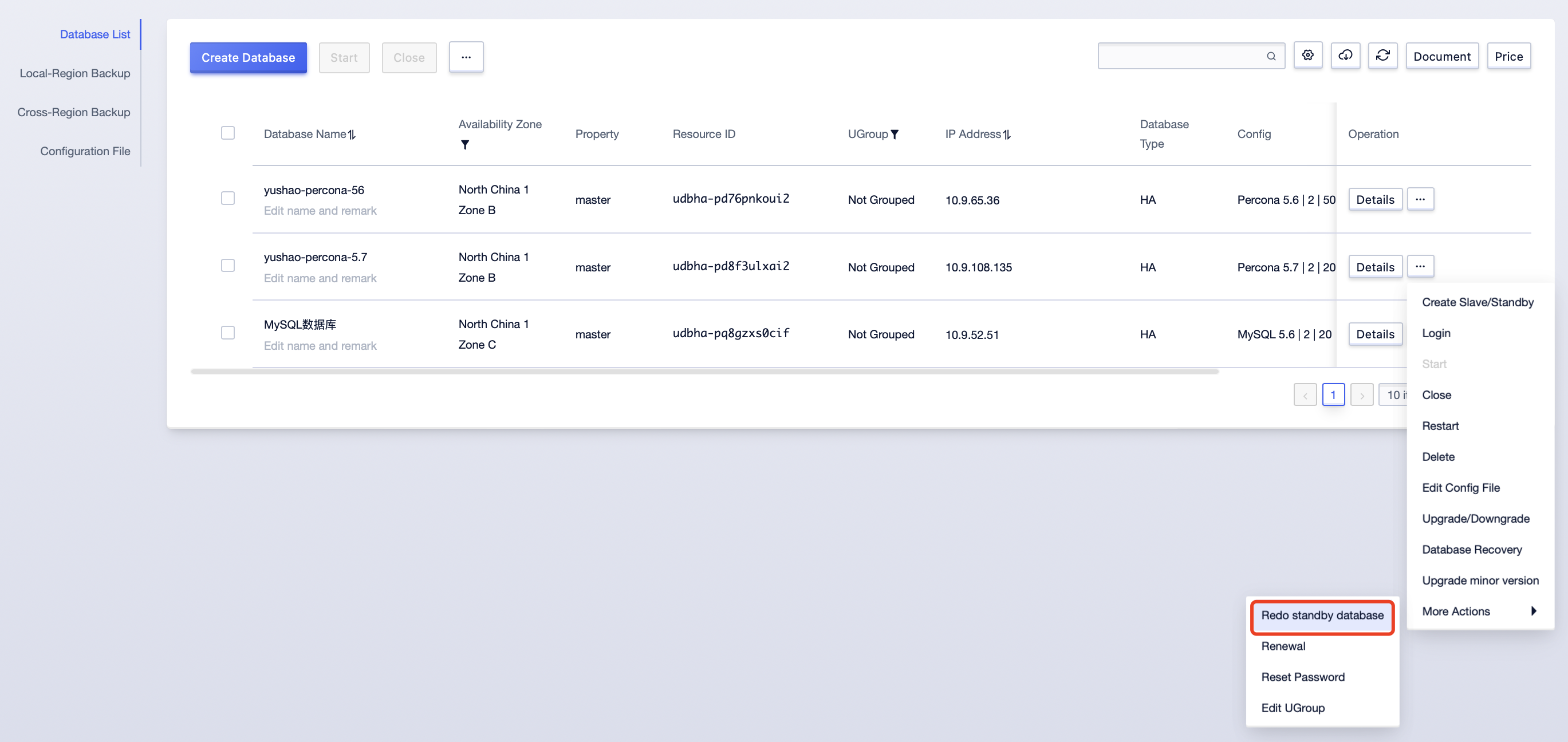
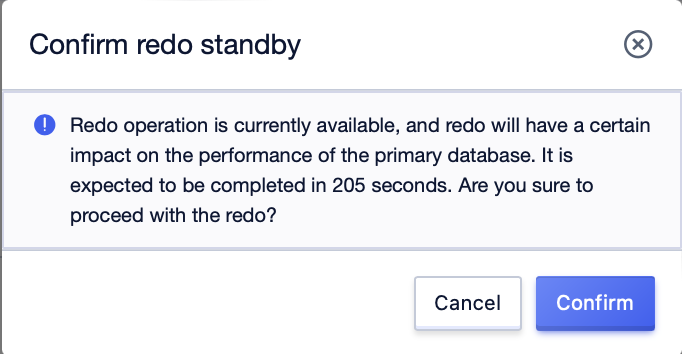
After releasing the space, wait for 2 minutes. If the high availability is still abnormal and the HAHealthState is 3,4, try to redo the standby database. Redoing the standby database will export data from the master database for data recovery. Before initiating the redo, a pre-check of the redo conditions will be carried out. For instances without anomalies, you can directly click confirm to start the redo. For instances where the non-transaction engine size is more than 1G (affecting the lock table time of synchronizing the master database), instances with long transactions (long transactions will cause the redo to not get the lock and always be in the redo), and instances with incorrect replication relationships (unreasonable replication relationships will be erased), you need to manually check the force to start the redo.